Meridian Archive
Construire un système de gestion muséale qui ne craint pas. Le voyage désordonné de l'enfer Excel vers des bases de données vivantes.
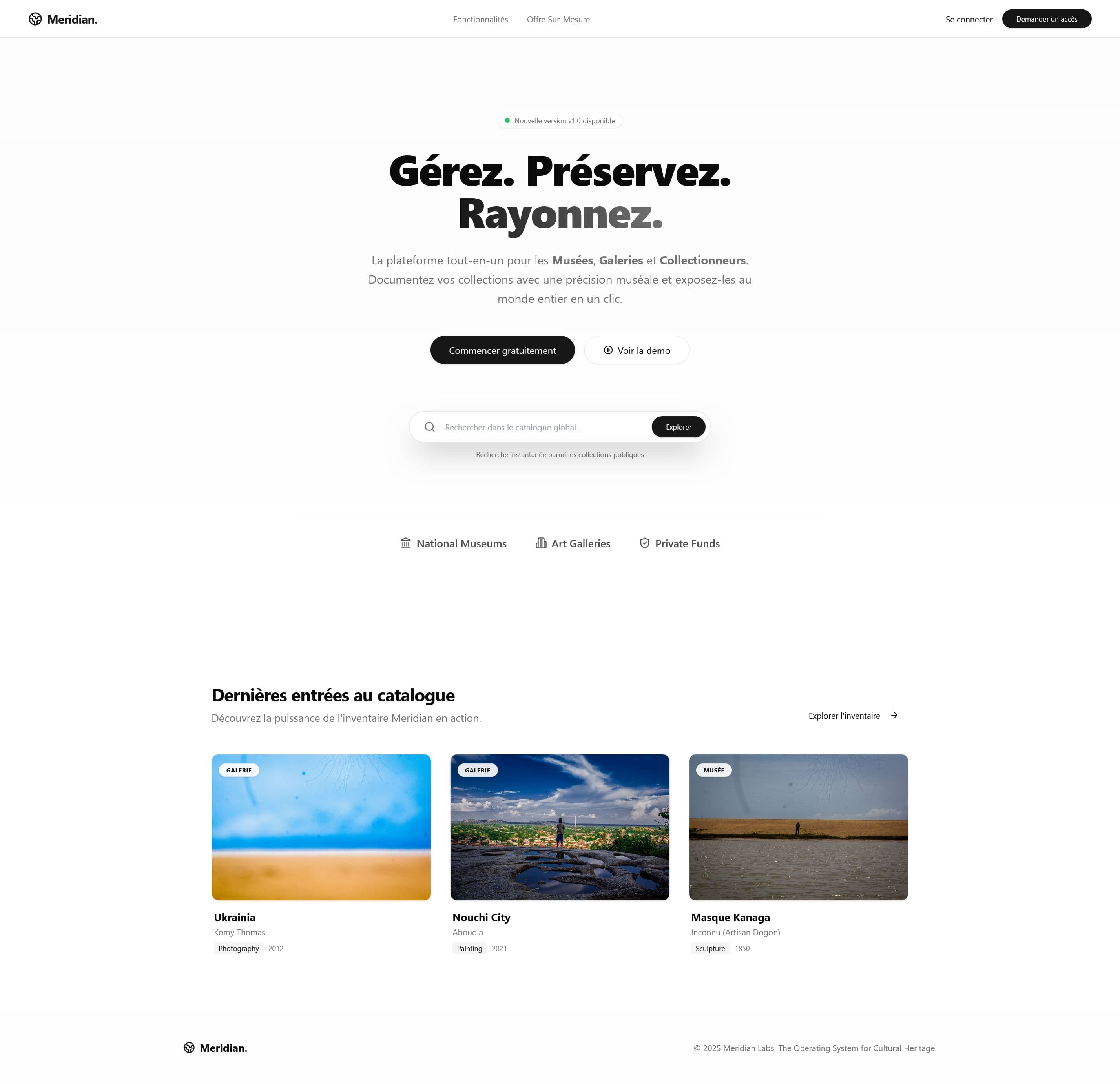
"Et si les musées pouvaient réellement chercher dans leurs propres collections ?"
Ce projet a commencé par une frustration que j'ai rencontrée en 2023 en travaillant avec un petit musée au Bénin. La conservatrice m'a montré leur "catalogue numérique"-un tableur Excel de 400 lignes avec un formatage incohérent, des liens d'images cassés, et aucune fonction de recherche au-delà du Ctrl+F.
Quand j'ai demandé comment ils trouvaient des artefacts spécifiques, elle a ri : "On se rappelle juste où les choses sont. Ou on demande au personnel plus ancien."
C'est là que j'ai réalisé : la plupart des musées africains tournent encore sur une infrastructure des années 1990. Pas parce qu'ils s'en fichent, mais parce que les logiciels modernes de gestion de collections coûtent $20,000-50,000 par an en frais de licence. Pour des institutions avec des budgets annuels de $10,000, c'est des maths impossibles.
Alors j'ai commencé à construire Meridian Archive.
L'idée : un os muséal pour tous
La vision initiale était simple : créer un système de gestion de collections gratuit et open-source qui suivait les standards internationaux mais ne nécessitait pas un doctorat en informatique pour être utilisé.
Je voulais trois choses :
- Conforme aux standards : Utiliser Dublin Core pour les métadonnées et Spectrum 5.1 pour la documentation muséale (pour que les catalogues soient compatibles avec les réseaux de recherche mondiaux)
- Réellement rapide : Recherche en temps réel à travers des milliers d'artefacts (pas les gels Excel de 30 secondes auxquels les conservateurs étaient habitués)
- Capable hors ligne : Parce que le wifi muséal au Bénin rural est... optimiste au mieux
Construire en public (plus ou moins)
J'ai commencé en janvier 2024, construisant les soirs et weekends entre les projets clients. La première version était honteusement basique-une interface CRUD avec PostgreSQL et une barre de recherche. Pas d'authentification. Pas d'uploads d'images. Juste des champs texte et un bouton submit.
Mais je l'ai quand même montré à la conservatrice du musée. Sa réaction ? "Attends, je peux chercher par matériau ? Et c'est instantané ?"
Ce petit moment de joie a tout validé.
Les parties difficiles
La Migration de Données c'est l'Enfer
Chaque musée a des décennies de données héritées dans différents formats-documents Word, bases FileMaker, cartes manuscrites scannées en PDF. Convertir ce chaos en enregistrements de catalogue propres et structurés est brutal.
J'ai construit des scripts ETL (Extract-Transform-Load) personnalisés pour chaque institution. Un musée avait des noms d'artefacts en français et en fon mélangés aléatoirement dans le même champ. Un autre avait des dimensions listées comme "petit", "moyen", "grand" au lieu de centimètres.
Il n'y a pas de bouton "import" qui répare ça. C'est de l'archéologie manuelle.
Le Trou de Lapin IIIF
Je voulais que Meridian Archive soit interopérable avec les plateformes de recherche mondiales comme Europeana et JSTOR. Ça signifiait implémenter le International Image Interoperability Framework (IIIF).
J'ai passé trois mois à lire des documents de spécification et construire un serveur IIIF personnalisé. Les musées ont-ils demandé ça ? Pas vraiment. Je trouvais ça cool ? Absolument. Ça a retardé des fonctionnalités plus importantes ? ...oui.
Leçon apprise : Ne pas dorer l'infrastructure quand les utilisateurs veulent juste uploader des photos plus rapidement.
Financement vs. Fonctionnalités
Les musées n'ont pas d'argent pour des abonnements logiciels. Alors comment je maintiens ce projet ?
J'ai essayé trois modèles :
- Totalement gratuit (m'a épuisé, ne pouvait pas payer l'hébergement)
- SaaS Freemium (les musées ne comprenaient pas le pricing d'abonnement)
- Hybride services clients (frais d'installation + formation pour institutions, logiciel core gratuit)
Je suis actuellement sur le modèle #3. Ça marche... à peine. Les revenus couvrent l'hébergement et mon temps pour les corrections de bugs critiques, mais le développement de fonctionnalités est lent.
Convaincre les Conservateurs
La partie la plus difficile n'est pas technique-c'est la confiance. Je demande aux conservateurs de migrer le travail de leur vie d'Excel (qu'ils comprennent) vers mon app web (qu'ils ne comprennent pas).
J'ai appris à passer les trois premières réunions juste à écouter. Comprendre leurs workflows. Leur montrer que je respecte leur expertise. Seulement alors je peux faire la démo du logiciel.
Une conservatrice m'a dit : "Jeune homme, j'ai vu cinq 'solutions numériques' aller et venir en 20 ans. Pourquoi devrais-je croire que vous serez encore là dans 5 ans ?"
Question juste. Ma réponse : documentation extrême et code open-source. Même si je disparais, le système peut survivre.
Où on en est maintenant
Meridian Archive est en bêta active avec 3 musées partenaires au Bénin. De vraies collections sont gérées quotidiennement. Le système gère ~15,000 enregistrements de catalogue à travers les sites pilotes.
Victoires récentes :
- Un musée a retrouvé un artefact qu'ils pensaient perdu (il était mal catalogué sous le mauvais type de matériau-la recherche a réglé ça)
- L'export vers IIIF fonctionne et leur collection est maintenant visible dans Europeana
- Le PWA mobile permet aux conservateurs de travailler hors ligne dans les réserves sans wifi
Défis honnêtes :
- Les uploads d'images sont encore trop lents (je travaille sur le pipeline de compression)
- L'UI est fonctionnelle mais pas belle (le design n'est pas ma force)
- L'adoption au-delà des sites pilotes est lente (la confiance prend du temps)
Et après ?
Je ne cours pas après la croissance hockey-stick. C'est du travail d'infrastructure-lent, délibéré, peu glamour.
Court terme :
- Améliorer l'expérience d'upload d'images
- Ajouter le support multi-langue pour les champs de catalogue (Français/Fon/Yoruba)
- Écrire une meilleure documentation d'onboarding
Long terme :
- Lancement public avec option de déploiement auto-hébergé (mi-2026)
- Construire une communauté de volontaires tech muséale qui peuvent aider à maintenir la codebase
- Peut-être explorer le financement par subventions (mais je suis allergique à la bureaucratie)
Ce projet m'a appris que le bon logiciel ne concerne pas les algorithmes malins-c'est comprendre les workflows réels des gens et construire des outils qui disparaissent dans leurs mains.
Les musées méritent mieux que l'enfer Excel.
Vous travaillez dans le patrimoine culturel ?
Ce logiciel est encore en développement actif. Si vous êtes professionnel de musée, archiviste ou institution culturelle intéressé à tester ou collaborer sur des outils de gestion de collections, j'aimerais vous entendre : komy@atilebarts.com