Meridian Archive
Building a museum management system that doesn't suck. The messy journey from Excel hell to living databases.
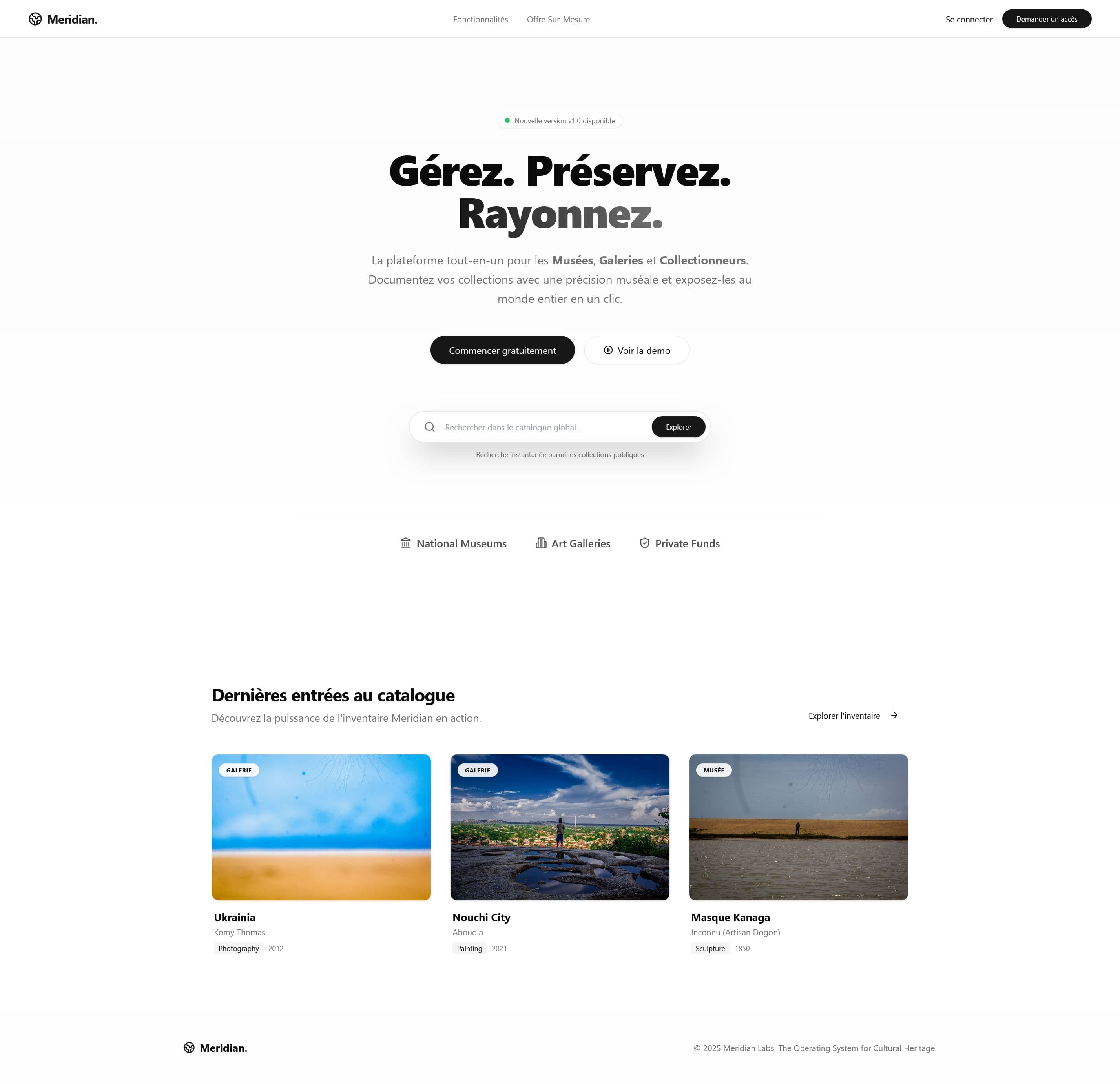
"What if museums could actually search their own collections?"
This project started with a frustration I encountered in 2023 while working with a small museum in Benin. The curator showed me their "digital catalog"-a 400-row Excel spreadsheet with inconsistent formatting, broken image links, and no search function beyond Ctrl+F.
When I asked how they found specific artifacts, she laughed: "We just... remember where things are. Or we ask the older staff."
That's when I realized: most African museums are still running on 1990s infrastructure. Not because they don't care, but because modern collection management software costs $20,000-50,000 per year in licensing fees. For institutions with annual budgets of $10,000, that's impossible math.
So I started building Meridian Archive.
The idea: museum os for everyone
The initial vision was simple: create a free, open-source collection management system that followed international standards but didn't require a PhD in computer science to use.
I wanted three things:
- Standards-compliant: Use Dublin Core for metadata and Spectrum 5.1 for museum documentation (so catalogs would be compatible with global research networks)
- Actually fast: Real-time search across thousands of artifacts (not the 30-second Excel freezes curators were used to)
- Offline-capable: Because museum wifi in rural Benin is... optimistic at best
Building in public (sort of)
I started in January 2024, building nights and weekends between client projects. The first version was embarrassingly basic-a CRUD interface with PostgreSQL and a search bar. No authentication. No image uploads. Just text fields and a submit button.
But I showed it to the museum curator anyway. Her reaction? "Wait, I can search by material? And it's instant?"
That tiny moment of delight validated everything.
The hard parts
Data Migration is Hell
Every museum has decades of legacy data in different formats-Word documents, FileMaker databases, handwritten cards scanned to PDF. Converting this mess into clean, structured catalog records is brutal.
I built custom ETL (Extract-Transform-Load) scripts for each institution. One museum had artifact names in French and Fon randomly mixed in the same field. Another had dimensions listed as "small", "medium", "large" instead of centimeters.
There's no "import" button that fixes this. It's manual archaeology.
The IIIF Rabbit Hole
I wanted Meridian Archive to be interoperable with global research platforms like Europeana and JSTOR. That meant implementing the International Image Interoperability Framework (IIIF).
I spent three months reading spec documents and building a custom IIIF server. Did museums ask for this? Not really. Did I think it was cool? Absolutely. Did it delay more important features? ...yes.
Lesson learned: Don't gold-plate infrastructure when users just want to upload photos faster.
Funding vs. Features
Museums don't have money for software subscriptions. So how do I sustain this project?
I tried three models:
- Fully free (burned me out, couldn't pay for hosting)
- Freemium SaaS (museums didn't understand subscription pricing)
- Client services hybrid (installation + training fees for institutions, free core software)
I'm currently on model #3. It's working... barely. Revenue covers hosting and my time for critical bug fixes, but feature development is slow.
Convincing Curators
The hardest part isn't technical-it's trust. I'm asking curators to migrate their life's work from Excel (which they understand) to my web app (which they don't).
I've learned to spend the first three meetings just listening. Understanding their workflows. Showing them I respect their expertise. Only then can I demo the software.
One curator told me: "Young man, I've seen five 'digital solutions' come and go in 20 years. Why should I believe you'll still be here in 5?"
Fair question. My answer: extreme documentation and open-source code. Even if I disappear, the system can survive.
Where we are now
Meridian Archive is in active beta with 3 partner museums in Benin. Real collections are being managed daily. The system handles ~15,000 catalog records across the pilot sites.
Recent wins:
- One museum found an artifact they thought was lost (it was miscataloged under the wrong material type-search fixed that)
- Export to IIIF is working and their collection is now visible in Europeana
- Mobile PWA lets curators work offline in storage rooms without wifi
Honest challenges:
- Image uploads are still too slow (working on compression pipeline)
- The UI is functional but not beautiful (design isn't my strength)
- Adoption beyond pilot sites is slow (trust takes time)
What's next
I'm not chasing hockey-stick growth. This is infrastructure work-slow, deliberate, unglamorous.
Short-term:
- Improve the image upload experience
- Add multi-language support for catalog fields (French/Fon/Yoruba)
- Write better onboarding documentation
Long-term:
- Public launch with self-hosted deployment option (mid-2026)
- Build a community of museum tech volunteers who can help maintain the codebase
- Maybe explore grant funding (but I'm allergic to bureaucracy)
This project has taught me that good software isn't about clever algorithms-it's about understanding people's actual workflows and building tools that disappear into their hands.
Museums deserve better than Excel hell.
Working in cultural heritage?
This software is still in active development. If you're a museum professional, archivist, or cultural institution interested in testing or collaborating on collection management tools, I'd love to hear from you: komy@atilebarts.com